
When I started working in Cyber security, one of the terms I heard a lot of, was Splunk. I was intrigued to find out more about this, as it seemed to be something that could help me advanced my knowledge.
So, what is Splunk? Splunk is software used to analyze security event data collected from devices and systems and determine if the collected data has any threats. Threats are prioritized by Splunk based on their severity, creating incidents which allow security analysts to decide on how to respond to them. Splunk uses threat intelligence, machine learning, behavior analysis to determine the severity of threats.
Splunk is a Security Incident and Event Management (SIEM) tool that ingests data from different resources and assets, analyzing these for potential threats and determining the level of criticality of the threat.
Like other SIEM tools, Splunk collects (ingests) large volumes of data, indexing this into a form it can work with and then through it’s analysis algorithms and artificial intelligence (machine learning) models, can look for patterns and determine potential issues.
Issues flagged up by Splunk based on their severity are used Security Operations Center (SOC) analysts to assess the level of incident, to see whether it is real and not a false positive. Real incidents are then triaged based on their severity, those incidents that can affect large parts of an organization can end up having to be dealt with as part of major incident management (MIM).
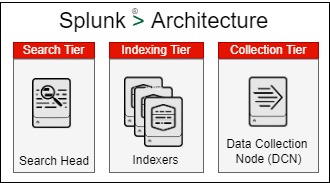
Splunk Architecture
There are three common areas associated with Splunk Architecture, the Indexing Tier, Search Tier and the Collection Tier. This multi-tier architecture provides a platform for collection information, analyzing it and then being able to use the resultant information by searching against it.
The information collected arrives at the collection tier in different formats from structured to unstructured the data. The Indexing Tier takes this data and using a number of processes, makes the data usable for analysis and searching.
Complex searching and querying can then be done on the data, allowing organizations to quickly grasp the security landscape based on the information ingested from various sources across the organization.
Collection Tier
Splunk needs data to be able to run it’s analysis algorithms and produce the dashboards as well as reports of information required by organizations when it comes to security incident and event management.
The Collection Tier includes a number of components that allow organizations to be able to collect log source data from a number of devices such as:
- Microsoft® Windows® based devices (laptops, workstations to servers)
- Linux based devices (laptops, workstations to servers)
- MacOS based devices (laptops, workstations)
- Networking devices (routers, firewalls to network access control devices)
The Collection Tier also has components allowing it to collect data from services like those in the cloud:
- Azure Active Directory
- Office 365 Management logs
- AWS CloudTrail, AWS Guard Duty, AWS VPC Flow logs
The Collection Tier includes one or more Data Collection Nodes (DCN), which are responsible for collecting data from the sources like devices to cloud services. The DCNs gathers the available data from multiple sources, into a single source for the indexing tier to use. Some of the DCNs are able to filter data collected from sources by relevance, thereby reducing the amount of data the Indexing Tier receives but at the same time maintaining the quality and usefulness of the data being collected.
Indexing Tier
The Indexing Tier takes in the collected data from the DCNs and by using specialized algorithms starts the process on improving the usability of the data collected. Ensuring it’s normalized for operation and indexed accordingly, along with compressing and encrypting the data for storage and security respectively.
The indexing is vitality important as the data needs to be easily queried by human and machine based queries, which can be quite complex and sophisticated. As the information required needs to be performed quickly, in near real-time capability and with poor indexing the availability and usefulness of the information becomes questionable.
The indexing tier is in essence a large database that is scaled to deal with large amounts of data that needs to be carefully and quickly sorted, so it can be used by analyzing it for patterns and techniques that can reveal security issues in the devices and sources from where the data was originally collected.
Search Tier
Once the data has been processed in the Indexing Tier, the Search Tier provides the ability for users to be able to search against the data, analyzing large volumes of data for insights into security issues. A search head in the Search Tier provides the capability to search the data, by acting as the central processing point for the data within the indexing tier.
The search head is smart enough to be able to perform the searching across multiple indexers within the indexing tier. The search head performs optimized searches, allowing users to quickly get access to the relevant data.
Accessing the search heads in the search tier relies on a web based User Interface (UI), which allows users to search data, build specific dashboards and run many different reports. Configuration settings for users with privileged levels of access like administrators, allows for improvements in security to the optimization of searches, leading to faster responses.
There is also a premium Search Head that can run Splunk apps like Enterprise Security and the Splunk IT Service Intelligence (ITSI). Splunk Enterprise Security (SES) provides a security posture view, looking at continuous security monitoring, advanced threat detection to incident response.
Whilst ITSI is a monitoring and analytics offering that uses artificial intelligence for IT Operations (AIOps), looking at potential threats, correlations of events for patterns to machine learning behavior analysis. Both SES and ITSI are available at extra cost, requiring specialized licenses.
Collection Tier Data Collection Nodes (DCNs)
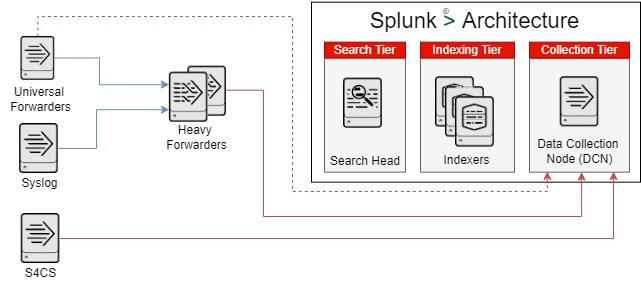
To be able to collect data, a number of different types of Data Collection Nodes can be used, individually or in combination to get the log sources from devices and cloud services into the Indexing tier of Splunk.
Universal Forwarders
The Universal Forwarder is software (client or an agent) running on a server computer (virtual or physical) that collects logs, events to performance metrics from devices and services configured to send data to it. The Universal Forwarder can become a single point to receive data from hundreds to thousands of devices. Devices can include Microsoft Windows based and Linux based devices, and networking devices with compatible logging formats.
The Universal Forward is unable to do any filtering of the data it collects and simply acts as a proxy passing on data to the Indexing Tier or to a Heavy Forwarder upstream.
Heavy Forwarders
The Heavy Forwarder like the Universal Forwarder is software, but it is designed to connect securely to the Indexers in the Indexing Tier, and can filter as well as transform the data they collect. Allowing for data to be parsed in a way where anything that’s not required, can be removed as it passes through the Heavy Forwarder.
So, if there’s personally identifiable information (PII) like customer names or even PCI DSS information like credit card numbers, these can be expunged from the data collected before it reaches the Indexing Tier.
Generally, the Heavy Forwarders provide the single point of connectivity (egress) out to Indexers in the Indexing Tier, with the Universal Forwarders connecting to them and sending the data they collect to the Heavy Forwarder.
Thereby, if the connection to the indexing tier is over the internet, the Heavy Forwarder can be the single secure connection, where the data passed over an encrypted connection instead of having multiple devices sending their data over the internet to the Indexing Tier. Many of these devices might not also be able to send their data using a secure encrypted connection, which in effect leaves the data vulnerable to being snooped upon by unauthorized individuals.
Splunk Connect for Syslog (S4CS)
Splunk Connect for Syslog commonly known as S4CS is software is a syslog server based on syslog-ng and runs as a containerized workload. It is able to collect data based on the syslog format and is able to connect securely to the Indexing servers in the Indexing Tier.
One of the issues the S4CS server was designed to meet was getting raw data easily from devices and systems and processing this, to make it easier to ingest in the Indexing Tier. Organizations don’t need to spin up their own syslog servers and worry about configuration and optimization, as the S4CS is ready to go and includes the ability to filter data, like the Heavy Forwarders.
HTTP Event Collector (HEC)
The HTTP Event Collector (HEC) provides a load balanced API for ingesting log data from cloud providers, Software as a Service (SaaS) vendors and on-premises services able to provide REST API integration. Data is transferred over secure HTTP (HTTPS) protocol, to protect against snooping and eavesdropping.
It makes sense to use the HEC as direct integration where an API can be used, instead of re-routing log data into other environments and using Heavy Forwarders. As this indirect method can likely incur additional costs especially in terms of data transfer costs.
Universal Forwarder vs Heavy Forwarder vs S4CS
The following table highlights the main differences between the Universal Forwarders, Heavy Forwarders and the Splunk Connect for Syslog (S4CS).
| Splunk Universal Forwarder | Splunk Heavy Forwarder | Splunk Connect for Syslog (S4CS) |
| Splunk Universal Forwarder software | Splunk Enterprise software | syslog-ng image (containerized workload) |
| Collect data and sends this to Indexers or Heavy Forwarders | Receives data from Universal Forwarders and sends it to other Splunk Instances | Collects data and sends this to Indexers |
| Unable to parse data | Parses data, including Line breaking, timestamp extraction and extracting index-time fields | Parses data, including Line breaking, timestamp extraction and extracting index-time fields |
| Unable to index data | Indexing data is optional subject to licensing | Indexing data is optional subject to licensing |
| Built-in license. No additional license required | Forwarder license required (free OMB licenses from Splunk Support) | Open Source licensing |
| Software developed by Splunk | Software developed by Splunk | Open Source software |
Deployment Servers
Splunk provide Deployment Servers which can be used to manage other Splunk servers including the Universal Forwarders, Heavy Forwarders and the Splunk Connect for Syslog (S4CS). This allows for a centralized configuration that can be propagated to the other Splunk servers, saving time and effort of visiting each Splunk server and updating the configuration.
Splunk Enterprise vs Splunk Cloud
The Splunk Enterprise is more a self hosted solution, where organizations can use their own environments in the cloud or within their own data centers (on-premises) where they can install and configure all the components within the Collection Tier, Indexing Tier and Search Tier.
All maintenance required as well as set up and configuration of Splunk Enterprise needs to be done by the Splunk Enterprise customer and in many instances Splunk consultants will be used by customers to set up their Splunk Enterprise solution. Consultant help with optimizing the solution to work efficiently in processing log data as well as configuring reporting and associated dashboards.
Whilst with Splunk Cloud, the Indexing Tier and Search Tier, with some elements of the Data Collection Tier are part of a managed service provided by Splunk and hosted in the cloud. Customers don’t need to deploy or configure servers for the search or indexing tier, or manage these servers.
Splunk expertise ensures the Splunk Cloud instance is optimized for use and the customer only needs to log into the their account created in Splunk Cloud to get access to the dashboards and the reports.
Splunk Cloud is hosted by Splunk in their own private instance of Amazon Web Services (AWS) cloud and uses many high availability options and services provided by AWS to ensure that Splunk Cloud remains operational.
Splunk Enterprise, as it’s self hosted will need to include measures for high availability like using multiple servers for different components, so if one fails, the service is still operational. Along with redundancy from using components that can carry on working when they fail, like data disks which can be mirrored or use another RAID combination to carry on being operational when one of the disks fails.
| Splunk Enterprise | Splunk Cloud |
| Hosted by the customer | Hosted by Splunk |
| Managed by the customer | Managed by Splunk |
| Receive data directly from devices | Does not accept directly sent device data, data must be routed via Splunk Forwarder (Heavy, Universal or S4CS) or HEC. |
| Native level alerts as the operating system level can be configured | Native level alerts at the operating system are not available |
| Compatible apps don’t need to be vetted | Only vetted apps can be run in Splunk Cloud |
| Components can be accessed using Command Line Interfaces (CLI) | No CLI access as the infrastructure is managed and owned by Splunk |
Wrap Up
Splunk provides two great options for SIEM including the Splunk Enterprise solution for customers to host themselves and the Splunk Cloud managed service, hosted by Splunk themselves. Both of these offerings have an Collection Tier, Indexing Tier and Search Tier with Splunk Cloud version hosting the Search, Indexing Tiers and partial Collection Tiers in the cloud.
Splunk data collection nodes like Universal Forwarders, Heavy Forwarders and Splunk Connect for Syslog (S4CS), collect data from assets and resources within data centers, cloud services to SaaS software. Ingesting the security logs and events that can be analyzed by Splunk for any potential threats.